VistaDB 5.1 Dramatically Speeds Up, Well, Everything!
While doing performance testing on the optimizer improvements for VistaDB 5.1 we found an issue that just couldn’t be addressed in the optimizer. We found a query that pretty well hits the worst case of this problem:

In this case the two tables in question – Session and Session_Detail – are joined on their primary key.
With VistaDB 5.0, this query takes a ridiculously long time – 9:44. No one would ever wait for that result. More importantly, it just intuitively doesn’t make sense: This kind of thing is going to happen all the time in a correctly formed query on a well normalized database. We had to fix it. Of course, there’s a fundamental problem if you’re loading hundreds of thousands of rows at a time but lets ignore that for the moment – people do that kind of thing.
What’s subtly the problem here is the join from the first table to the second cable causes the second table to be walked in a random order. The first table is walked in table order (since there’s no filter and there’s no Order By) which is very efficient but the join to the second table means the engine has to look up rows one-by-one by their primary key. Since the test database uses UniqueIdentifier for its keys (and even if it didn’t, there’s no reason to assume table order is key order) it’s as if we wanted to randomly load rows from anywhere in the table. While the engine does perform caching of pages, randomly plucking rows out of a large table is not going to result in very good cache hit ratios.
At the lowest level of the VistaDB engine we noticed that it’s spending a lot of effort deserializing data for index pages – way more than it should in some cases. It turns out that back when VistaDB 3 was created a tradeoff was made between object oriented design simplicity and performance – namely that whenever a page is loaded all of the contents of the database page are deserialized into objects before any of it can be accessed. This approach makes the API cleaner and less risky, but lets say you just want to read one value out of one row on a page – that’s a lot of work you then end up throwing away! When the engine is randomly accessing values in an index (as opposed to walking them in order) this results in a dramatic number of index rows deserialized compared to the number that are actually used. The overhead of this adds up.
Across the Board Improvement
To address this we’ve changed the engine so it defers parsing each row out of a page until that row is required. This applies to indexes and the table data itself, so the biggest benefit shows up when hunting down a single row in an index: At each level of the index tree it only has to deserialize the minimum number of rows to find the row it’s looking for.
After implementing this improvement we re-ran the original test – The performance improved dramatically from 9:44 down to 1:20 – Over 7 times faster. Now, this is still a long time but it reflects a worst case scenario with a large data set.
This type of behavior happens a lot in a database – any time a table is joined in (because for each value on the left side it has to look up the value on the right) or when finding a row by its primary key. For example, this helps on updates and inserts as well: Not just speeding up finding the row to insert or update but also minimizing the effort it takes to rewrite the row that changed since it doesn’t have to rewrite every row in the page like it did previously.
Insert Performance
We did a quick test of inserting 10,000 rows into a simple multi-column table.
| VistaDB 4.3 | VistaDB 5.0 | VistaDB 5.1 |
|---|---|---|
| 38.25 seconds | 38.32 seconds | 20.18 seconds (47% Improvement) |
That’s right – nearly twice as fast. Tables with foreign key references see an even bigger improvement since the FK lookup done on insert to verify data integrity. This is particularly nice since improving bulk insert performance is a common request – everyone needs to load up initial data in a database and we’re glad to get this gain.
Faster Updates Too
To check the effect on updates we set up a test with 10,000 random updates to a table with 1 million rows. By randomly picking rows we ensured engine caching would be largely defeated.
| VistaDB 4.3 | VistaDB 5.0 | VistaDB 5.1 |
|---|---|---|
| 99.73 seconds | 90.32 seconds | 24.47 seconds (75% Improvement) |
A reduction of 75% means updates are four times faster under 5.1. As with inserts, foreign key references see an even bigger improvement.
Bringing it All Together
Combining these new improvements to the storage engine with the previous improvements to the optimizer in 5.1 and we get this updated chart of performance test results:
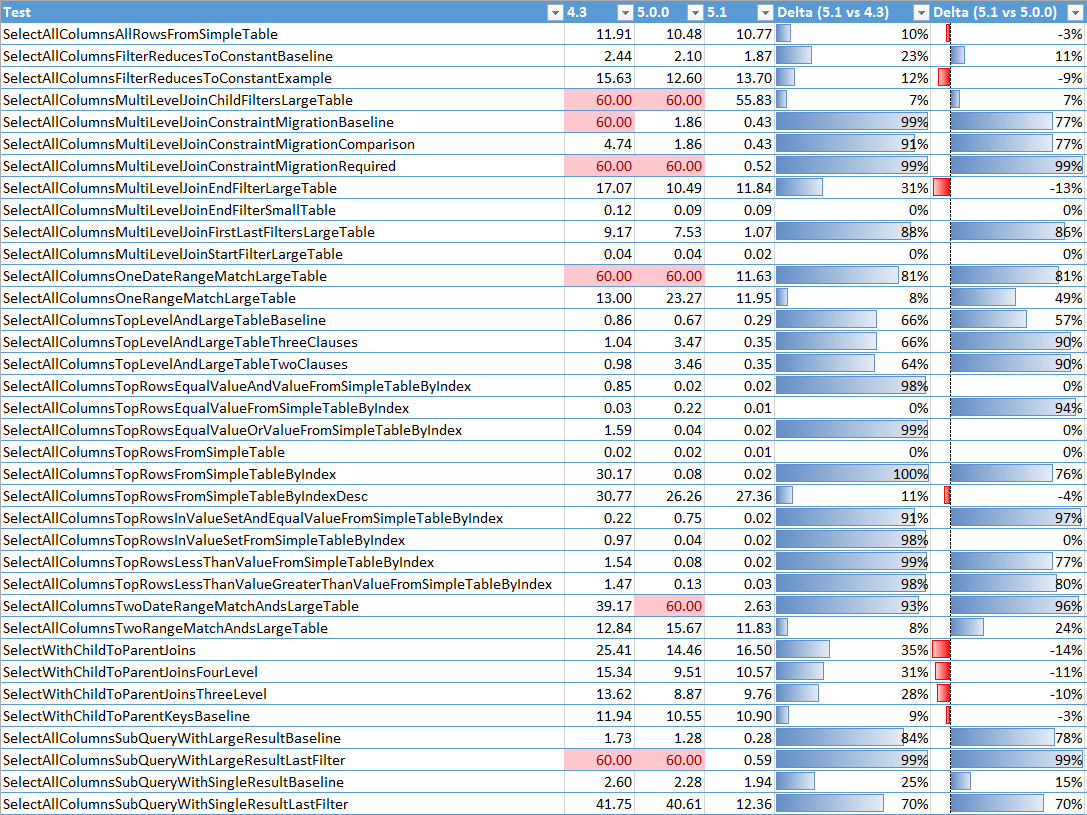
The previous improvements to the optimizer addressed the scenarios where queries were going out to lunch and generally ensuring an efficient execution path got selected. Our latest storage engine changes build on that to find a further – often a further two or three times faster! What’s particularly nice is the number of queries that went from two seconds to sub-second. These go from needing to be run in the background to being effectively real-time.
Trying it Out for Yourself
Unfortunately, to make these improvements work we’ve had to change the file format. Previously, VistaDB serialized certain fields in a way that depended on all previous values in the same page. The previous format required deserializing all of the rows in a page – which causes the performance problem we are fixing. So, we’ve changed the file format to eliminate this dependency and done a few other minor tweaks to improve performance. This means to get this performance advantage a database has to be packed to upgrade to the latest file format. This in turn also means we’ve had to update the assembly version of the engine to prevent unexpected compatibility issues.
Because of these breaking changes and the very low odds of negative performance side effects of this change we’re holding these changes until the 5.1 release version so you won’t see this in the beta versions.