VistaDB 5.1 Beta – Optimizer Upgrades for Faster Queries
We just shipped VistaDB 5.0.5 but for the past eight months we’ve been spending most of our time on a much bigger deal – a new optimizer that really ups the bar on how VistaDB analyzes queries.
It’s All About That Perf
Let’s face it, when it comes to databases you can never have enough speed. Since data is read far more often than it’s updated that means query performance is where it counts. Like SQL Server, for VistaDB this comes down to taking the T-SQL query and determining the fastest way to execute it. VistaDB has always had an optimizer – it determined:
- What indexes to use: Filtering results by an index is faster than reading all the rows in the table.
- What’s constant: What part of a query isn’t going to change for the life of a query (even if it isn’t coded as a constant)
- When to recalculate values: To process joins efficiently, only re-evaluate constraints and joins that could have changed as rows are processed.
Unlike SQL Server, VistaDB has always focused on optimizing the query it was given as opposed to rewriting it into a more efficient form. This is a largely pragmatic decision both given the high complexity of a query rewriting and the embedded nature of VistaDB requiring it to be essentially stateless, giving very little time to evaluate a query. Up through VistaDB 5 the optimizer used a built-in set of rules to determine how to select an index, when to create a temporary index, and when to apply constraints. These rules were based in assumptions of typical queries and index structures. VistaDB 5 introduced new sophistication to the optimizer – including using multicolumn indexes for filtering and using indexes to optimize ORDER BY statements to avoid re-sorting in memory.
This generally improved performance in 5.0 – in some cases dramatically. However, after 5.0 shipped some customers reported certain queries that were oddly slow. In many cases, these queries were just as slow or worse in VistaDB 4 but in a few cases these were regressions with 5.0. As we dug into these cases we detected a few problems:
- Too many indexes: The zeal of the new optimizer to create temporary indexes could cause it to burn time creating indexes that ultimately didn’t benefit performance.
- Over optimize OR clauses: A specialized filter used for combining multiple OR clauses together would spend too much time setting up an optimized query relative to the amount of time it takes to just evaluate the data.
A New Approach
From these problems we saw a root cause – The optimizer didn’t take into account the actual data’s characteristics when determining what to do. SQL Server keeps statistics on its indexes and tables to guide the optimizer. VistaDB doesn’t do this, but fortunately we’ve found ways to get reasonable metrics on the fly. VistaDB 5.1’s optimizer now does a few nice tricks:
- Apply constraints in the best order: Even when using indexes it takes effort to evaluate each column and narrow the results. Ideally you want to narrow down the results as fast as possible.
- Quit when you’re good enough: If the number of candidate matching rows is small enough it’s faster to just load the remaining rows and process them instead of doing the additional work to merge in subsequent indexes.
- Make temp indexes when you’re sure: It takes real work to make a temporary index, so be sure when you do it that there’s good odds it’ll make the query faster. That means it would have to notably reduce the number of rows that are ultimately processed. Otherwise, it’s faster to just iterate the rows.
Put another way, the optimizer now takes into account the actual data in your database to determine the most effective strategy to execute the query.
Let’s Prove It Works
This approach is a bit dangerous – it means if the optimizer guesses wrong you could have oddly bad performance, and it could be inconsistent. To head this risk off we’ve done a lot of testing and validation to make sure we have the right cut over points and testing methods. We’ve developed a set of unit tests based on boundary conditions we’ve seen in our analysis:
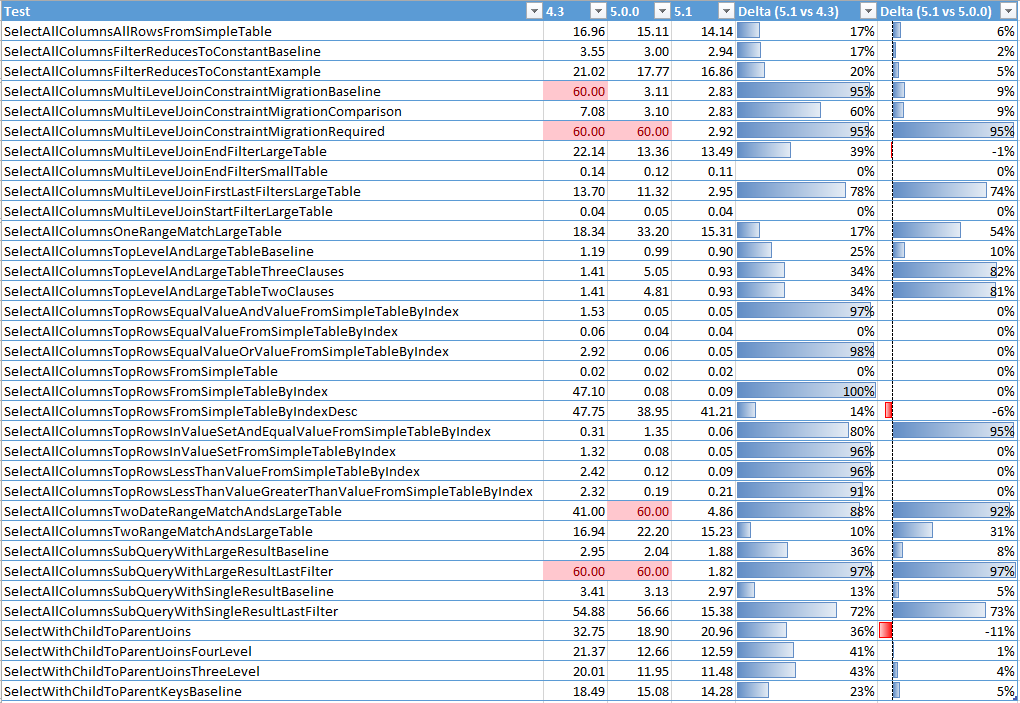
What’s the final tally? Of the 29 scenarios we focused on in 9 (26%) we compellingly out-perform VistaDB 5 and in 14 (41%) we compellingly out-perform VistaDB 4. And by “compelling” I mean “more than 50% faster”. And when are we slower than VistaDB 4 or 5? Basically never within the tolerance of our testing.
By the way, this testing isn’t with some weedy little database; our sample database is from a conversion of our SQL Server database of the Loupe data we collect for our development & beta teams- Gigabytes of database. Most queries were done against tables with hundreds of thousands or millions of rows. We wanted to be sure we were looking at data that would force the optimizer to work or die trying.
Here’s Where You Come In
But, we’ve learned that nothing matches the experience of real world queries – so the purpose of this preview release is to get as much public experience with our new optimizer as possible. From our testing, it’s faster than any previous release of VistaDB. But it doesn’t matter that it’s faster for us – it matters that it’s faster for you. So, give the preview a shot and let us know if you can stump the optimizer. We have additional logging in the preview build so we can see exactly what the optimizer is thinking and make it smarter. VistaDB 5.1 preview will install as an in-place upgrade for VistaDB 5 so you can’t have it and our current release version installed on the same computer; it’ll also place itself in the GAC so even if you have a reference to an older build of VistaDB on your computer you’ll get the new preview edition. All of that is to say you should consider where you want to install the preview before leaping in. You can always uninstall it and re-install VistaDB 5 to roll back.
Path to Release
From the Beta to Release we have a few things to complete:
- Ensure no Performance Regressions: We want to make sure there isn’t a query out there we haven’t thought of where 4.3 or 5.0 is faster than what we’re doing now. If you think you’ve got one to stump us with, please send it in to support@gibraltarsoftware.com or online at support.gibraltarsoftware.com.
- Improve Temp Index Generation: We have momentarily turned off temp indexes in most cases because integrating them into the new optimizer is turning out to be very tricky (without it potentially causing the same problems it can cause in 5.0.
And one more thing… While digging through one oddly slow query we discovered a performance issue with the underlying way VistaDB manages index storage. We’ve run a few experiments with quite promising results. An initial rough experiment with an improved storage algorithm resulted in a dramatic improvement in performance to 14 of 37 scenarios. What makes this particularly nice is how well it works together with the new optimizer – since it speeds up loading index data and rows based on an index it makes a good index selection strategy even more effective.
We have to ring out a few details before we can be confident in going forward with it, but we’ll cover that in a future post.