VistaDB 4.3 Performance Optimization
We are happy to announce the biggest update to the VistaDB engine since Gibraltar Software took over the product last year. It’s actually our fifth update, though our earlier releases were more limited in scope consisting of a new streamlined licensing system and a number of bug fixes—often providing closer compatibility with SQL Server scripts.
The main focus of VistaDB 4.3 is query performance, particularly with multiple JOINs. We’re pleased to report 2.5x improvements in many cases and discuss below what’s happening inside the VistaDB engine to achieve these results. Let’s start with an overview of how VistaDB produces query results.
How Does My Query Work?
VistaDB queries are executed in three general phases:
- Parse: The SQL query text is parsed into a tree of objects representing each language element.
- Prepare: The statement/expression tree is recursively processed to identify table and column references and to determine the data types of results.
- Execute: The statement/expression tree is recursively processed to execute statements and provide results in order (returning to the calling application as each row is ready).
If there were no optimizations at all, the engine would walk every row of the parent table. And for each of those rows, then walk every row of the first joined table looking for matches to the ON clause. For each of those rows it would then repeat the process for every row of every additional table referenced in the query. Obviously, this would be ridiculously slow when joining multiple tables of any real size, or even when querying a single table with a large number of rows when you don’t actually want most of them.
To be more efficient, VistaDB performs an additional optimization step at the start of the Execute phase. This step recursively walks the WHERE clause and ON clauses and converts the comparison expressions (and special functions such as BETWEEN) into a more efficient representation as constrains in which each constraint specifies a range of values for a particular column based on constants, parameter values, or the value of a column from an earlier table in the parse tree.
In optimizing the parse tree, VistaDB simplifies the execution plan into a series of constrained tables you could imagine as being evaluated left-to-right. Constraints that can’t be resolved are declared non-optimizable and must be handled by testing the WHERE clause. Similarly, target columns for which there isn’t an available index are also non-optimizable and must be tested row-by-row. These optimized conditions are then processed for logical ANDs and ORs to calculate an overall optimized filter for each table.
Building On What Already Works Well
VistaDB has always done well with queries in which a range of rows can be retrieved on a single-column index with an identifiable starting and ending value based on the current rows of tables “to the left” of it. For example, if the parent (FROM) table is restricted by a single comparison in the WHERE clause such as: WHERE ParentTable.ColA = @ChosenValue; (with an index on ColA), then the engine doesn’t need to walk every row of ParentTable, it can start with the first row in the index with a value of @ChosenValue for ColA, and walk each row in the index until it passes the last row with a value of @ChosenValue for ColA. If another table is then joined in it doesn’t need to consider any combinations outside of that range on ParentTable; they’re already certain to be excluded by that condition in the WHERE clause.
Improvements in VistaDB 4.3
We use VistaDB extensively in our Gibraltar application monitoring system and noticed that VistaDB performance left something to be desired for some of our more complex queries. For example, it is common to use a placeholder ID (perhaps a UNIQUEIDENTIFIER) as a foreign key into a small lookup table which can contain additional information fields universal to that value. In Gibraltar we have tables such as Application_Type and Boot_Mode which provide caption and description labels for display purposes. They can be joined directly into a query about one or more sessions, like so:
SELECT * FROM Session_Details SD JOIN Processor_Architecture OSA ON OSA.PK_Architecture_Id = SD.FK_OS_Architecture_Id JOIN Boot_Mode BM ON BM.PK_Boot_Mode_Id = SD.FK_OS_Boot_Mode_Id JOIN Processor_Architecture RA ON RA.PK_Architecture_Id = SD.FK_Runtime_Architecture_Id
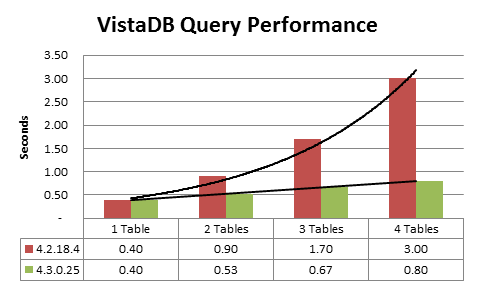
The joined tables are tiny, only 5 or so rows each, so (in theory) this should be very efficient. Each joined table can have its unique matching row directly looked up based on the corresponding column value in the parent table. Perfect, right? But this query was taking several seconds. The base query (SELECT * FROM Session_Details) took less than half a second, and that’s querying the entire table! What we found in VistaDB 4.2 was that as each JOIN was added to this query, the overall query time nearly doubled! Something was clearly less efficient than it should be.
As we analyzed the engine internals, we found a lot of opportunities to improve performance which we’ll be implementing over the coming year. As a first step, we decided to focus in VistaDB 4.3 on reducing the overhead for multiple joins and optimize for the most common cases.
We expect that the majority of joins will be on a single equality between a single column from each table with a foreign key relationship between them. Since this should by definition identify a single value (and often a single row), it should be the most efficient filter to narrow down the joined table based on those “to the left”. So the optimization logic will now catch these top-priority conditions early on and bypass the rest of the expensive reduction pass.
And in queries like our example, we integrated column value caching to eliminate the need to search for the same rows over and over again. When a table is joined on a UNIQUE single column index, the table can cache the row in a Dictionary keyed by the column value from the other table, and each time it comes back to that value, it grabs the row from cache instead of searching the index and reading it from disk again.
We also coded our caching to ensure that it doesn’t consume excessive memory when processing large tables. The cache only holds hard references to the most recently accessed rows. By using weak references to less recently used rows they stick around when memory is plentiful but can be garbage-collected if necessary. For more info on on weak references, check out Kendall’s Code Project article and sample code on creating a single instance string store.
As shown in the graph above, VistaDB 4.3 is several times faster for many common queries. More importantly, in queries such as above, performance degrades linearly as more tables are joined, rather than exponentially as before.
Stay Tuned for More to Come
The query optimizations we’ve introduced in VistaDB 4.3 are just a start. Subsequent releases will have additional query optimizations as well as other performance improvements such as support for bulk insert and enhanced multi-user scalability. We also will be adding new features such as enhanced support for Entity Framework, enhanced compatibility with SQL Server and improvements to our development tools (Data Builder, Data Migration Wizard, etc).
We’ll be writing additional blog posts about our adventures taking VistaDB to the next level, so check back often or leave a question/comment below or in our support forums –we’d love to hear from you!