VistaDB – Insert if Not Exists Performance
Last weekend I was lying in bed, waiting for my wife to get out of the shower, thinking about how I’d build an application that I had an idea for. It was an information collection and analysis application, where I’d be taking information, from various sources, collating the data then reporting on it. I realised that I’d need my database inserts to be idempotent, i.e. I’d need “Insert if Not Exists” behaviour.
Now, as all of us developers know, the database is just a storage repository, a giant PC peripheral, think of it as a very big USB stick if you will. So, even though this problem can be solved with the use of stored procs on the server, I wasn’t going to take that route. ![]()
Keeping all the code on “my side of the fence” leaves me with two main patterns to codify this behaviour. The first is to check for the existence of the row I want to insert and, if it doesn’t already exist, insert it. The second is to insert the row regardless and then catch the duplicate row exception from the database. The only question remaining is, which is the optimal solution?
Intuitively I know that catching the exception is expensive, but is it more expensive than testing before each and every insertion? There’s only one way to find out, design an experiment and run some tests.
Now, in this experiment, we want to know two things. Which of the two patterns is optimal, and does that result vary as the number of rows already in the database increases? So, we need a table with a good spread of fields across the available data types. For each iteration of the experiment we’ll double the number of rows already in the database, compared to the previous iteration. We’ll attempt to insert 10% of the number of rows already in the database and we’ll record the time (in milliseconds) for each pattern. The first iteration will have 100 rows in the database and we’ll stop at rows = 25,600. In case there are any transient machine specific issues that might slew our results, we’ll run the test 10 times and take an average.
First we need to design a table, something like this should suffice:
Next we have to set up an unique index on one of the columns. For the purposes of this experiment we’ll pick col2.
That done, the process for running the tests is as follows:
static void Main()
{
RunTests();
AccumulateResults();
AverageResults();
WriteFinalResults();
}
What will happen here is that the tests will be run, and the results written out to a CSV file. Next, each file will be read in and the values accumulated and averaged, before a final results CSV file is written.
As you can see from the code below, the tests are run 10 times (NUM_TIMES_REPEAT == 10) and for each test we test the “Catch” and “Check” patterns with database sizes growing exponentially from 100 to 25,600, before writing the result of each test to a CSV file.
private static void RunTests()
{
conn.Open();
while (ctr <= NUM_TIMES_REPEAT)
{
Console.WriteLine("Starting run {0}", ctr);
results.Clear();
int[] numRows = new int[] { 100, 200, 400, 800, 1600, 3200, 6400, 12800, 25600 };
foreach (int i in numRows)
{
Console.WriteLine("Processing rows = {0}", i);
TimeAddingTenPercentOfRowsWithCatch(i);
TimeAddingTenPercentOfRowsWithCheck(i);
}
Results2CSV(ctr);
ctr++;
}
conn.Close();
}
Within the test for the “Catch Pattern” we attempt to add the row, catch and swallow the unique constraint error and re throw any other errors.
private static void InsertRow(VistaDBCommand cmd)
{
try { cmd.ExecuteNonQuery(); }
catch (VistaDBException e)
{
const int UNIQUE_CONSTRAINT_ERR = 309;
if (((VistaDBException)e.GetBaseException()).ErrorId == UNIQUE_CONSTRAINT_ERR)
{
//GS - Swallow error, row does not get added;
}
else
{
//GS - DB has thrown another type of error so re throw it
throw;
}
}
}
Whilst in the “Check Pattern” , we test for the existence of the row and if it’s not present we insert it:
private static void TimeAddingTenPercentOfRowsWithCheck(int numRows)
{
EmptyTable();
SetUpTableWithRows(numRows);
int numRowsToAdd = (int)(numRows * 0.1);
Stopwatch sw = new Stopwatch();
sw.Start();
for (int i = 0; i < numRowsToAdd; i++)
{
string query = String.Format("select * from Data where col2 = '{0}'", TARGET_DATE);
Object result = null;
using (VistaDBCommand cmd = new VistaDBCommand(query, conn))
{
result = cmd.ExecuteScalar();
}
if (result == null)
{
InsertRowNoTry(GetInsertCmdForTestRow());
Console.WriteLine("Shouldn't see this!");
}
}
sw.Stop();
results[numRowsToAdd][1] = sw.ElapsedMilliseconds;
}
Notice the check and the insert are not protected with a transaction, this is because the database file was opened in Exclusive R/W mode and so no other process could have inserted a duplicate row between our check and our insert.
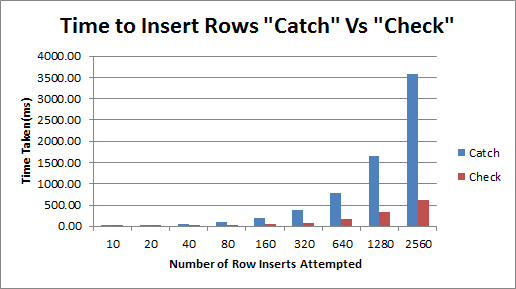
So, having run the tests and analysed the data, what were the results?
As you can see from the graph below, the “Check” pattern was consistently the more performant option when it comes to application side “Insert if Not Exists” type behaviour.
The second question we wanted to answer was “is this performance consistent over a growing database?” From the graph below, you can see that it is.
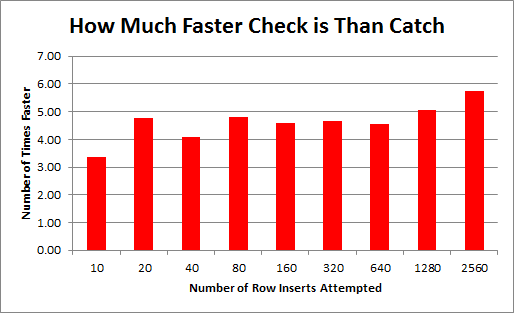
On average, the “Check Pattern” is 4.62 times faster than the “Catch Pattern” and with a standard deviation of just 0.64 it seems that “power up” remains pretty consistent across table size.
So there you have it, if you need “Insert if Not Exists” behaviour use the “Check Pattern”. Until next time, happy coding…